L’expression intelligence artificielle a été inventée par John McCarthy il y a quarante ans. Une définition représentative s’articule autour de la comparaison de machines intelligentes avec des êtres humains. Une autre définition concerne la performance des machines qui, historiquement, ont été considérées comme relevant du domaine du renseignement.
Pourtant, aucune de ces définitions n’a été universellement acceptée, probablement parce que la référence au mot intelligence est une quantité incommensurable.
Qu’est-ce que l’intelligence artificielle ?
Une meilleure définition de l’intelligence artificielle, et probablement la plus précise serait :
Un système artificiel capable de planifier et d’exécuter la bonne tâche au bon moment et de manière rationnelle. Ou beaucoup plus simple : une machine qui peut agir rationnellement.
Questions sur l’intelligence artificielle
- La pensée et l’action rationnelles englobent-elles toutes les caractéristiques d’un système intelligent ?
- Si oui, comment représente-t-elle l’intelligence comportementale telle que l’apprentissage, la perception et la planification ?
Un système capable de raisonner serait un bon planificateur. De plus, un système ne peut agir rationnellement qu’après avoir acquis des connaissances du monde réel. Ainsi, la perception est un avantage de l’acquisition de connaissances du monde réel. Une machine qui manque de perception ne peut pas apprendre, donc ne peut pas acquérir de connaissances.
Approches générales de résolution de problèmes avec l’ ai
Pour comprendre le sens l’intelligence artificielle, il faut illustrer quelques problèmes communs. Tous les problèmes qui sont traités avec des solutions d’intelligence artificielle utilisent le terme commun “état”.
Un état représente l’état d’une solution à une étape donnée de la procédure de résolution de problème. La solution d’un problème est un ensemble d'”états”. La procédure ou l’algorithme de résolution de problème applique un opérateur à un “état” pour obtenir l’état suivant. Ensuite, il applique un autre opérateur à l’état résultant pour en dériver un nouvel état.
Le processus d’application des opérateurs à chaque état se poursuit jusqu’à ce qu’un objectif souhaité soit atteint.
Exemple : Considérons un problème à 4 casse-tête, où dans un tableau à 4 cellules, il y a 3 cellules remplies de chiffres et 1 cellule vide. L’état initial du jeu représente une orientation particulière des chiffres dans les cellules et l’état final à atteindre est une autre orientation fournie au joueur. Le problème du jeu est d’atteindre de l’état initial donné à l’état but (final), si possible, avec un minimum de coups. Soit l’état initial et l’état final comme indiqué dans la figure:

Nous définissons maintenant deux opérations, blank-up (BU) / blank-down (BD) et blank-left (BL) / blank-right (BR), et l’espace d’état (arbre) du problème est présenté ci-dessous en utilisant ces opérateurs. L’algorithme pour le type de problèmes ci-dessus est simple. Il comprend trois étapes, décrites aux étapes 1, 2(a) et 2(b) ci-dessous.
Algorithme pour résoudre des problèmes d’espace d’états
Commencer
1-. state: = initial-state; existing-state:=state;
2-.While state ≠ final state do
Begin
a. Apply operations from the set {BL, BR, BU, BD} to each state so as to generate new-states;
b. If new-states ∩ the existing-states ≠ φ
Then do
Begin state := new-states – existing-states;
Existing-states := existing-states – {states}
End;
End while;
End.

Il est clair que le principal truc pour résoudre les problèmes par l’approche de l’espace d’états est de déterminer l’ensemble des opérateurs et de l’utiliser aux états appropriés du problème.
Les chercheurs en intelligence artificielle ont distingué les problèmes d’IA des autres problèmes. En général, les problèmes pour lesquels des algorithmes mathématiques/logiques simples ne sont pas facilement disponibles et qui ne peuvent être résolus que par une approche intuitive, sont appelés problèmes d’IA.
Le problème des 4 énigmes, par exemple, est un problème d’IA idéal. Il n’y a pas d’algorithme formel pour sa réalisation, c’est-à-dire, étant donné un état de départ et un état de but, on ne peut pas dire avant l’exécution des tâches la séquence des étapes nécessaires pour obtenir le but de l’état de départ. De tels problèmes s’appellent les problèmes idéaux de l’IA.
Le problème bien connu de la cruche d’eau, le problème du vendeur itinérant et le problème de la n-Queen sont des exemples typiques des problèmes classiques de l’IA.
Parmi les problèmes non classiques de l’IA, les problèmes de diagnostic et de classification des modèles méritent une mention spéciale. Pour résoudre un problème d’IA, on peut utiliser à la fois l’intelligence artificielle et des algorithmes non-AI. Une question évidente est : qu’est-ce qu’un algorithme d’IA ?
Algorithme d’IA
Formellement parlant, un algorithme d’intelligence artificielle signifie généralement une approche intuitive non conventionnelle pour la résolution de problèmes. La clé de l’approche de l’intelligence artificielle est la recherche et l’appariement intelligents. Dans un problème ou sous-problème de recherche intelligente, dans un état de but (ou de départ) donné, il faut atteindre cet état à partir d’un ou plusieurs états de départ (ou de but) connus.
Par exemple, considérons le problème des 4 puzzles, où l’état du but est connu et où l’on doit identifier les mouvements pour atteindre le but à partir d’un état de départ prédéfini. Maintenant, moins on génère d’états pour atteindre l’objectif, mieux c’est. C’est l’algorithme de l’IA.
La question qui se pose alors naturellement est : comment contrôler la génération des États ?
Ceci peut être réalisé en concevant des stratégies de contrôle appropriées, qui ne filtreraient que quelques états à partir d’un grand nombre d’états juridiques qui pourraient être générés à partir d’un état de départ / intermédiaire donné.
Prenons l’exemple du problème de la preuve d’une identité trigonométrique que les enfants ont l’habitude de faire pendant leur scolarité. Que feraient-ils au début ? Ils commenceraient par un côté de l’identité et tenteraient d’y appliquer un certain nombre de formules pour trouver les dérivations possibles.
Mais ils n’appliqueront pas vraiment toute la formule là-bas. Ils identifient plutôt la bonne formule candidate qui convient, de sorte que l’autre côté de l’identité qui semble être plus proche dans un certain sens (perspective). En fin de compte, lorsque la décision concernant le choix de la formule est terminée, ils l’appliquent à un côté (disons le L.H.S) de l’identité et en tirent le nouvel état.
Par conséquent, ils continuent le processus et continuent à générer de nouveaux états intermédiaires jusqu’à ce que le R.H.S. (but) soit atteint. Mais choisissent-ils toujours la bonne formule pour un état donné ? D’après notre expérience, nous savons que la réponse est “pas toujours”. Mais que ferions-nous si nous découvrions qu’après la génération de quelques états, l’expression résultante semble être loin de la R.H.S. de l’identité.
Peut-être préférerions-nous passer à un ancien État plus prometteur, c’est-à-dire plus proche de la R.H.S.S. de l’identité. La ligne de pensée ci-dessus a été réalisée dans de nombreux problèmes de recherche intelligente de l’IA.
Certains de ces algorithmes de recherche bien connus sont :
a) Générer et tester
b) Escalade de colline
c) Recherche heuristique
d) Analyse des moyens et des finalités
a) Générer et tester l’approche :
Cette approche concerne la génération de l’espace d’état à partir d’un état de départ connu (racine) du problème et continue d’étendre l’espace de raisonnement jusqu’à ce que le nœud visé ou l’état terminal soit atteint.
En fait, après avoir généré chaque état, le nœud généré est comparé à l’état objectif connu. Lorsque le but est trouvé, l’algorithme se termine. Dans le cas où il existe plusieurs chemins menant au but, alors le chemin ayant la plus petite distance de la racine est préféré. La stratégie de base utilisée dans cette recherche n’est que la génération d’états et leur test pour des objectifs, mais elle ne permet pas de filtrer les états.
(b) Approche de l’escalade :
Selon cette approche, il faut d’abord générer un état de départ et mesurer le coût total pour atteindre l’objectif à partir de l’état de départ donné. Soit ce coût f. Alors que f = une valeur d’utilité prédéfinie et que le but n’est pas atteint, de nouveaux nœuds sont générés comme enfants du nœud courant. Cependant, dans le cas où tous les nœuds de voisinage (états) donnent une valeur identique de f et que le but n’est pas inclus dans l’ensemble de ces nœuds, l’algorithme de recherche est bloqué face un problème insurmontable ou à un extrême local.
Une façon de surmonter ce problème est de sélectionner au hasard un nouvel état de départ, puis de poursuivre le processus de recherche ci-dessus. Tout en prouvant les identités trigonométriques, nous utilisons souvent l’escalade, peut-être sans le savoir.
(c) Recherche heuristique :
Classiquement heuristique signifie règle de base. Dans la recherche heuristique, nous utilisons généralement une ou plusieurs fonctions heuristiques pour déterminer les meilleurs états candidats parmi un ensemble d’états juridiques qui pourraient être générés à partir d’un état connu.
La fonction heuristique, en d’autres termes, mesure l’aptitude des pays candidats. Plus le choix des états est judicieux, moins il y aura d’états intermédiaires pour atteindre l’objectif.
Cependant, la tâche la plus difficile dans les problèmes de recherche heuristique est la sélection des fonctions heuristiques. Il faut les sélectionner intuitivement, de sorte que dans la plupart des cas, nous l’espérons, il sera en mesure d’élaguer correctement l’espace de recherche.
d) Analyse des moyens et des fins :
Cette méthode de recherche tente de réduire l’écart entre l’état actuel et l’état visé. Une façon simple d’explorer cette méthode est de mesurer la distance entre l’état actuel et le but, puis d’appliquer un opérateur à l’état actuel, de sorte que la distance entre l’état résultant et le but soit réduite. Dans de nombreux processus de démonstration de théorèmes mathématiques, nous utilisons l’analyse des moyennes et des fins.
Les disciplines de l’intelligence artificielle
Le sujet de l’intelligence artificielle s’étend sur un large horizon. Il traite de différents types de schémas de représentation des connaissances, de différentes techniques de recherche intelligente, de diverses méthodes pour résoudre l’incertitude des données et des connaissances, de différents schémas pour l’apprentissage automatique automatisé et bien d’autres.
Parmi les domaines d’application de l’intelligence artificielle, nous avons les systèmes experts, le gameplay et la théorie, le traitement du langage naturel, la reconnaissance d’images, la robotique et bien d’autres. Le sujet de l’intelligence artificielle s’est enrichi d’une vaste discipline de connaissances en philosophie, psychologie, sciences cognitives, informatique, mathématiques et ingénierie. C’est ce que montre la figure, ils ont été désignés comme les disciplines mères de l’IA. Un coup d’œil à la fig. révèle également le domaine d’application de l’IA et ses domaines d’application.
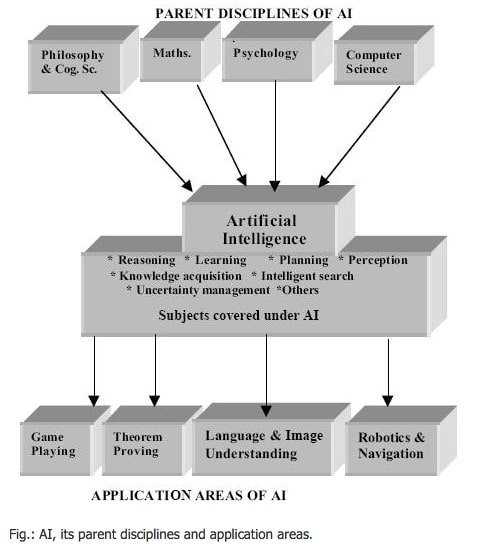
Fig.. : IA, ses disciplines d’origine et ses domaines d’application.
Le sujet de l’intelligence artificielle
Le sujet de l’intelligence artificielle a vu le jour grâce à des programmes de jeu et de démonstration de théorèmes et s’est progressivement enrichi des théories d’un certain nombre de disciplines parentales. En tant que jeune discipline scientifique, l’importance des sujets couverts par le sujet change considérablement avec le temps. À l’heure actuelle, les sujets que nous trouvons importants et utiles pour comprendre le sujet sont décrits ci-dessous :
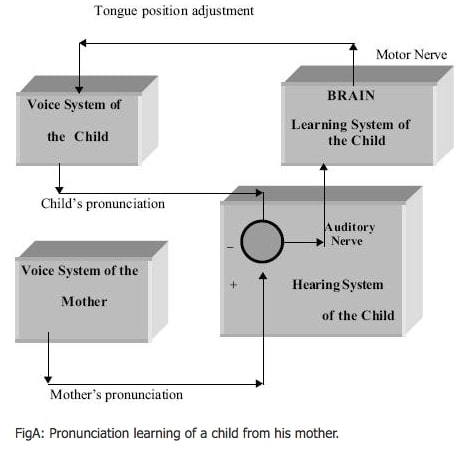
FigA : Prononciation de l’apprentissage d’un enfant de sa mère.
Systèmes d’apprentissage :
Parmi les domaines couverts par l’intelligence artificielle, les systèmes d’apprentissage méritent une mention spéciale. Le concept d’apprentissage est illustré ici en référence à un problème naturel d’apprentissage de la prononciation par un enfant de sa mère (voir figA). Le système auditif de l’enfant reçoit la prononciation du caractère “A” et le système vocal tente de l’imiter. La différence entre la prononciation de la mère et celle de l’enfant, ci-après appelée signal d’erreur, est reçue par le nerf auditif du système d’apprentissage de l’enfant, et un signal d’actionnement est généré par le système d’apprentissage via un nerf moteur pour ajuster la prononciation de l’enfant. L’adaptation du système vocal de l’enfant se poursuit jusqu’à ce que l’amplitude du signal d’erreur soit insignifiante. Chaque fois que le système vocal passe par un cycle d’adaptation, la position de la langue de l’enfant pour parler “A” est enregistrée par le processus d’apprentissage. Le problème d’apprentissage discuté ci-dessus est un exemple d’apprentissage paramétrique bien connu, où le processus d’apprentissage adaptatif ajuste les paramètres du système vocal de l’enfant de façon autonome pour maintenir sa réponse suffisamment proche du “modèle d’entraînement”. Les réseaux neuronaux artificiels, qui représentent l’analogue électrique des systèmes nerveux biologiques, gagnent en importance pour leurs applications croissantes dans les problèmes d’apprentissage supervisés (paramétriques). Outre ce type d’apprentissage, les autres méthodes d’apprentissage communes, que nous utilisons sans le savoir, sont l’apprentissage inductif et l’apprentissage par analogie. Dans l’apprentissage inductif, l’apprenant fait des généralisations à partir d’exemples. Par exemple, en notant que “mouches à coucou”, “mouches perroquets” et “mouches moineaux”, l’apprenant généralise que “les oiseaux volent”. D’autre part, dans l’apprentissage par analogie, l’apprenant, par exemple, apprend le mouvement des électrons dans un atome de manière analogue à partir de sa connaissance du mouvement planétaire dans les systèmes solaires.
Représentation et raisonnement des connaissances :
Dans un problème de raisonnement, il faut atteindre un état objectif prédéfini à partir d’un ou plusieurs états initiaux donnés. Ainsi, moins il y a de transitions pour atteindre l’objectif, plus l’efficacité du système de raisonnement est élevée. Augmenter l’efficacité d’un système de raisonnement nécessite donc de minimiser les états intermédiaires, ce qui nécessite indirectement une base de connaissances organisée et complète. Un réservoir de connaissances complet et organisé a besoin d’un minimum de recherche pour identifier les connaissances appropriées à un état problématique donné et ainsi produire le bon état suivant à la pointe du processus de résolution de problèmes. L’organisation du savoir est donc d’une importance capitale en ingénierie du savoir. Diverses techniques de représentation des connaissances sont utilisées en intelligence artificielle. Les règles de production, les réseaux sémantiques, les cadres, les remplisseurs et les fentes, la logique des prédicats ne sont que quelques-uns des éléments à mentionner. Le choix d’un type particulier de schéma de représentation des connaissances dépend à la fois de la nature des applications et du choix des utilisateurs.
Planification :
Un autre domaine important de l’intelligence artificielle est la planification. Les problèmes de raisonnement et de planification ont de nombreux points communs, mais ont une différence fondamentale qui provient de leurs définitions. Le problème de raisonnement concerne principalement la vérification de la satisfaction d’un objectif à partir d’un ensemble donné de données et de connaissances. Le problème de planification, d’autre part, concerne la détermination de la méthodologie par laquelle un objectif réussi peut être atteint à partir des états initiaux connus. La planification automatisée trouve de nombreuses applications dans la robotique et les problèmes de navigation, dont certains seront discutés prochainement.
Acquisition de connaissances :
L’acquisition de connaissances est aussi difficile pour les machines que pour les êtres humains. Elle comprend la production de nouvelles connaissances à partir d’une base de connaissances donnée, l’établissement de structures de données dynamiques pour les connaissances existantes, l’apprentissage des connaissances de l’environnement et le raffinement des connaissances. L’acquisition automatisée des connaissances par l’approche de l’apprentissage automatique est un domaine actif de la recherche actuelle en intelligence artificielle. Recherche intelligente : Les problèmes de recherche, que nous rencontrons généralement en informatique, sont de nature déterministe, c’est-à-dire que l’ordre de visite des éléments de l’espace de recherche est connu. Par exemple, en profondeur d’abord et en largeur d’abord les algorithmes de recherche, on connaît la séquence de visite des nœuds dans un arbre. Cependant, les problèmes de recherche, que nous rencontrerons dans l’IA, sont non déterministes et l’ordre de visite des éléments dans l’espace de recherche dépend entièrement des ensembles de données. La diversité des algorithmes de recherche intelligente sera discutée en détail plus loin.
Programmation logique :
Pendant plus d’un siècle, les mathématiciens et les logiciens ont été habitués à concevoir divers outils pour représenter les énoncés logiques des opérateurs symboliques. L’une des conséquences de ces tentatives est la logique propositionnelle, qui traite d’un ensemble d’énoncés binaires (propositions) reliés par des opérateurs booléens. La logique des propositions, qui s’est progressivement enrichie pour faire face à des situations plus complexes du monde réel, est appelée logique des prédicats. Une variété classique de programmes prédicats basés sur la logique est Logic Program. PROLOG, qui est l’abréviation de PROgramming en LOGic, est un langage typique qui supporte les programmes logiques. La programmation logique a récemment été identifiée comme l’un des principaux domaines de recherche en IA. Le but ultime de cette recherche est d’étendre le compilateur PROLOG pour traiter les modèles spatio-temporels et supporter un environnement de programmation parallèle. La construction de l’architecture des machines PROLOG a été un sujet d’actualité au cours de la dernière décennie.
Informatique douce :
L’informatique douce, selon le professeur Zadeh, est ” une approche émergente de l’informatique, qui fait écho à la remarquable capacité de l’esprit humain à raisonner et à apprendre dans un environnement d’incertitude et d’imprécision “. Il s’agit, en général, d’un ensemble d’outils et de techniques informatiques, partagés par des disciplines étroitement liées qui comprennent la logique floue, les réseaux neuronaux artificiels, les algorithmes génétiques, le calcul des croyances et certains aspects de l’apprentissage machine comme la programmation inductive. Ces outils sont utilisés indépendamment ou conjointement selon le type de domaine d’application.
Gestion de l’imprécision et de l’incertitude :
Les données et les bases de connaissances de nombreux problèmes typiques de l’IA, comme le raisonnement et la planification, sont souvent contaminées par diverses formes d’inachèvement. Le caractère incomplet des données, ci-après appelé imprécision, apparaît généralement dans la base de données en raison i) du manque de données appropriées et ii) du faible niveau d’authenticité des sources. Le caractère incomplet des connaissances, souvent appelé incertitude, trouve son origine dans la base de connaissances en raison du manque de certitude des éléments de connaissance. Différents outils et techniques ont été mis au point pour raisonner avec des données et des connaissances incomplètes. Certaines de ces techniques utilisent i) des modèles stochastiques ii) flous et iii) des modèles de réseaux de croyances. Dans un modèle de raisonnement stochastique, le système peut avoir une transition d’un état donné à un certain nombre d’états, de sorte que la somme de la probabilité de transition aux états suivants de l’état donné est strictement unitaire. Dans un système de raisonnement flou, par contre, la somme de la valeur d’appartenance de la transition d’un état donné à l’autre peut être supérieure ou égale à un. Le modèle du réseau de croyances met à jour la croyance stochastique / floue attribuée aux faits intégrés dans le réseau jusqu’à ce qu’une condition d’équilibre soit atteinte, après quoi il n’y aurait plus de changement dans les croyances. Récemment, des outils et des techniques flous ont été appliqués dans un réseau de croyances spécialisé, appelé “fuzzy Petri net”, pour traiter l’imprécision des données et l’incertitude des connaissances par une approche unifiée.
Applications des techniques d’intelligence artificielle
Presque toutes les branches de la science et de l’ingénierie partagent actuellement les outils et les techniques disponibles dans le domaine de l’intelligence artificielle. Cependant, pour la commodité des lecteurs, nous mentionnons ici quelques applications typiques, où l’intelligence artificielle joue un rôle significatif et décisif dans l’automatisation de l’ingénierie.
Systèmes experts :
Dans cet exemple, nous illustrons le processus de raisonnement d’un système expert pour un problème de prévision météorologique en mettant l’accent sur son architecture. Un système expert se compose d’une base de connaissances, d’une base de données et d’un moteur d’inférence pour interpréter la base de données à l’aide des connaissances fournies dans la base de connaissances. Le processus de raisonnement d’un système expert illustratif typique est décrit dans la Fig. PR 1 de la Fig. représente la i-ème règle de production. Le moteur d’inférence tente de faire correspondre les clauses antécédentes (parties FI) des règles avec les données stockées dans la base de données. Lorsque toutes les clauses antécédentes d’une règle sont disponibles dans la base de données, la règle est déclenchée, ce qui entraîne de nouvelles inférences. Les déductions qui en résultent sont ajoutées à la base de données pour activer le déclenchement ultérieur d’autres règles. Afin de conserver des données limitées dans la base de données, quelques règles qui contiennent une clause explicite (THEN) pour supprimer des données spécifiques des bases de données sont utilisées dans la base de connaissances. Lors de l’application de ces règles, les clauses relatives aux données non désirées, comme le suggère la règle, sont supprimées de la base de données. Ici PR1 fait feu car ses deux clauses antécédentes sont présentes dans la base de données. Lors de la mise à feu de PR1, la clause “it-will-will-rain” sera ajoutée à la base de données pour la mise à feu ultérieure de PR2.

Fig. architecture illustrative d’un système expert.
Compréhension de l’image et vision par ordinateur :
Une image numérique peut être considérée comme un ensemble bidimensionnel de pixels contenant des niveaux de gris correspondant à l’intensité de l’éclairage réfléchi reçu par une caméra vidéo. Pour l’interprétation d’une scène, son image doit passer par trois processus de base : la vision de bas, moyen et haut niveau.

Fig.. : Étapes de base de l’interprétation d’une scène.
L’importance de la vision de bas niveau est de prétraiter l’image en filtrant le bruit. Le système de vision de niveau moyen s’occupe de l’amélioration des détails et de la segmentation (c.-à-d., la division de l’image en objets d’intérêt). Le système de vision de haut niveau comprend trois étapes : reconnaissance des objets à partir de l’image segmentée, étiquetage de l’image et interprétation de la scène. La plupart des outils et techniques d’IA sont requis dans les systèmes de vision de haut niveau. La reconnaissance des objets à partir de son image peut s’effectuer par un processus de classification des motifs, qui est actuellement réalisé par des algorithmes d’apprentissage supervisés. Le processus d’interprétation, par contre, exige un calcul fondé sur les connaissances.
Compréhension de la parole et du langage naturel :
La compréhension de la parole et des langues naturelles est fondamentalement deux problèmes classiques. Dans l’analyse de la parole, le principal problème est de séparer les syllabes d’un mot parlé et de déterminer des caractéristiques comme l’amplification du son et les fréquences fondamentales et harmoniques de chaque syllabe. Les mots pourraient alors être identifiés à partir des caractéristiques extraites par des techniques d’identification de classe de motifs. Récemment, des réseaux de neurones artificiels ont été utilisés pour classer les mots à partir de leurs caractéristiques. Le problème de la compréhension des langues naturelles comme l’anglais, par contre, inclut l’interprétation syntaxique et sémantique des mots d’une phrase et des phrases d’un paragraphe. Les étapes syntaxiques sont nécessaires pour analyser les phrases par leur grammaire et sont similaires aux étapes de compilation. L’analyse sémantique, qui est effectuée à la suite de l’analyse syntaxique, détermine le sens des phrases à partir de l’association des mots et celui d’un paragraphe à partir de la proximité des phrases. Un robot capable de comprendre la parole dans un langage naturel sera d’une immense importance, car il pourra exécuter toute tâche qui lui sera communiquée verbalement. La machine à écrire phonétique, qui imprime les mots prononcés par une personne, est une autre invention récente où la compréhension de la parole est utilisée dans une application commerciale.
Ordonnancement :
Dans un problème d’ordonnancement, il faut planifier l’horaire d’un ensemble d’événements pour améliorer l’efficacité temporelle de la solution. Par exemple, dans un problème d’emploi du temps de routine, les enseignants sont affectés à des classes différentes à des créneaux horaires différents, et nous voulons que la plupart des classes soient occupées la plupart du temps. Dans un problème d’ordonnancement d’atelier, un ensemble de tâches J1 et J2 (disons) doit être affecté à un ensemble de machines M1, M2 et M3. (disons). Nous supposons que chaque travail nécessite certaines opérations à effectuer sur toutes ces machines dans un ordre fixe, disons M1, M2 et M3. Maintenant, quel devrait être l’horaire des travaux (J1-J2) ou (J2-J1), de sorte que le temps de réalisation des deux travaux, appelé make-span, soit minimisé ? Soit le temps de traitement des travaux J1 et J2 sur les machines M1, M2 et M3 respectivement (5, 8, 7) et (8, 2, 3). Les gantt charts de la fig. (a) et (b) décrivent les plages de fabrication pour l’horaire des travaux J1 – J2 et J2 – J1 respectivement. Il ressort clairement de ces chiffres que le calendrier J1-J2 nécessite moins de temps de préparation et qu’il est donc préférable.

Fig.. : Les diagrammes de Gantt pour le problème d’ordonnancement de l’atelier d’usinage avec 2 tâches et 3 machines.
Les problèmes d’ordonnancement de l’atelier de fabrication sont un problème NP complet et la détermination de l’ordonnancement optimal (pour minimiser la durée de fabrication) exige donc un ordre exponentiel du temps par rapport à la taille de la machine et à la taille du travail. Il est donc préférable de trouver une solution sous-optimale pour de tels problèmes d’ordonnancement. Récemment, des réseaux neuronaux artificiels et des algorithmes génétiques ont été utilisés pour résoudre ce problème. La recherche heuristique, qui sera discutée prochainement, a également été utilisée pour traiter ce problème.
Contrôle intelligent :
Dans le contrôle de processus, le contrôleur est conçu à partir des modèles connus du processus et de l’objectif de contrôle requis. Lorsque la dynamique de l’installation n’est pas complètement connue, les techniques existantes pour la conception des régulateurs ne sont plus valables. Un contrôle fondé sur des règles est approprié dans de telles situations. Dans un système de contrôle basé sur des règles, le contrôleur est réalisé par un ensemble de règles de production définies intuitivement par un ingénieur de contrôle expert. La partie antécédente (prémisse) des règles d’un système fondé sur des règles est recherchée par rapport à la réponse dynamique des paramètres de la centrale. La règle dont la partie antécédente correspond à la réponse de l’installation est sélectionnée et mise à feu. Lorsque plus d’une règle est applicable, le contrôleur résout le conflit par un ensemble de stratégies. D’autre part, il existe des situations où la partie antécédente qu’aucune règle ne correspond exactement aux réponses de l’usine. Ces situations sont les suivantes avec une logique floue, qui est capable de faire correspondre les parties antécédentes de partiellement / approximativement avec les réponses dynamiques de l’installation. La régulation floue a été utilisée avec succès dans de nombreuses installations industrielles. Un exemple typique est le contrôle de puissance dans un réacteur nucléaire. En plus de la conception de l’autre problème dans le contrôle de procédé est la conception d’une usine (procédé). qui tente de suivre la réponse de l’installation réelle, lorsque l’usine et l’estimateur sont excités conjointement par un signal d’entrée commun.
Les techniques d’apprentissage basées sur les réseaux de neurones flous et artificiels ont récemment comme de nouveaux outils d’estimation pour les usines.